DART
Data Analysis and Reporting Tool

DART is an intelligent data analysis tool that generates
automatic statistical analyses of clinical trials under
user supervision. This software was developed in Stata
programming language and is based on a complex algorithm
developed according to the considerations on statistical
methodology for clinical trials defined in the ICH
guidelines.
DART receives pre-processed data from PANDA. Its wizard-type
interface allows the user to define certain parameters
of the statistical analysis. Some of those parameters
are, for example, the method to be used for imputation
of missing values, scale transformations and adjustment
variables. Once DART has acquired all the necessary
information from the user, it performs automatically
all the required analyses, including the selection
of the appropriate statistical models, the presentation
of measures of effect size and their confidence intervals,
and the conversion of transformed variables to their
original scales. All calculations are performed by
Stata release 6 or higher, one of the most respected
statistical software packages.
The results of the efficacy analysis are sent to PANDA
for ultimate generation of the statistical tables.
As a final touch, DART saves all the data necessary
for the efficacy analysis in a flat file that can be
imported by any statistical software. This insures
that the user will be able to perform any additional
analysis in the uncommon instance that DART is not
able to perform all required analysis.
DART analyzes efficacy data of clinical trials with
any type of design, namely non-comparative trials,
two or more arm comparative trials, and factorial designs.
The single exception at this time is the analysis of
cross-over trials, whose implementation has not yet
been finished. DART can also be used in stand-alone
mode for the analysis of some kinds of observational
studies based on simple random sampling, namely case-control
studies and studies for the investigation of prognostic
factors.
The main characteristics of DART include:
• User guidance in the definition of the
specifications and selection of the parameters for
a statistical analysis
• Automated statistical analysis of clinical
trials in full compliance with ICH guidelines, including
descriptive statistics, analysis of heterogeneity across
centers and groups, primary and secondary efficacy
analyses, post-stratification analysis and sub-group
analysis
• Automatic verification of the assumptions
of regression models.
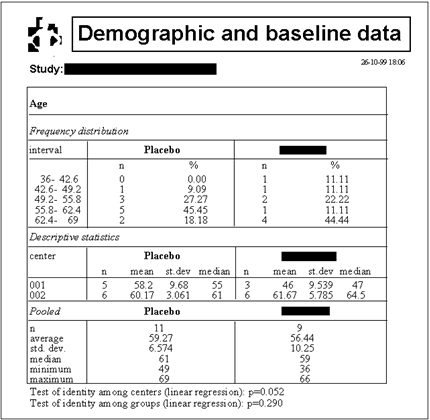
The example shown below illustrates the presentation
of the results of the descriptive analysis of demographic
and baseline data. The statistical methods selected
by DART that were used to test the heterogeneity of
centers and groups regarding the distribution of the
variable (age) are printed below the table. In this
particular case, DART selected linear regression as
the appropriate method.
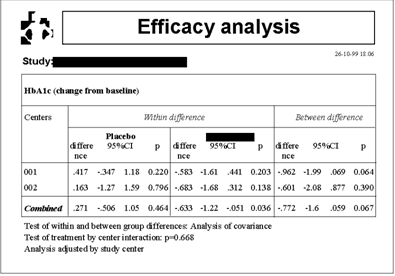
The following example shows the analysis of one of
the efficacy criteria of this clinical trial. In this
case, the efficacy variable is the change from baseline
of the value of A1c hemoglobin. The change from baseline
was the criteria defined by the user, who could optionally
have parameterized the analysis to use, for example,
the last observed value, the percent change from baseline
or the average of several values. DART displays, for
each center and for all centers combined, the within-
and between-group difference estimates, their 95% confidence
intervals and associated P-values. In each analysis,
DART always reports the selected statistical methods.
In this example we can see that, for the main analysis,
DART selected analysis of covariance with adjustment
by the baseline value of A1cHb; that DART tested the
treatment by center interaction and concluded that
the interaction was not statistically significant;
and that such conclusion determined that the efficacy
analysis was stratified by study center. The user has
not specified adjustment factors, or has not accepted
the factors suggested by DART, and therefore the analysis
was not adjusted for confounding.
This example illustrates well the importance to DATAMEDICA
of our clinical trials information system. Only to
test the formal hypothesis of a clinical trial it is
necessary to perform three analysis for each study
center, for each efficacy variable and for each efficacy
population. This means that for a medium sized clinical
trial with, for example, 15 centers and 6 efficacy
variables, 864 calculations will be necessary to determine
difference estimates, confidence limits and P-values,
assuming that 3 efficacy population are being used
as recommended. Using traditional methods, the almost
2,600 calculations necessary just for the efficacy
analysis take weeks to perform and are very prone to
transcription errors; with DART, there are no transcription
errors and all those analysis and tables take less
than a minute to create.
The extraordinary performance of DATAMEDICA's clinical
trials information system is very relevant to the study
sponsor. It means that, once the CRF data is entered
into COATI, the final statistical report will be completed
in a period of time measured in days.
The tables created automatically by DART include:
Primary efficacy population
Demographic and baseline data with heterogeneity tests
Testing of between and within-group differences
Efficacy data over time
Post-stratification analysis
Subgroup analysis
Secondary efficacy population
Demographic and baseline data with heterogeneity tests
Testing of between and within-group differences
Efficacy data over time |