PANDA
Data Analysis Package

PANDA is a database application designed for clinical
trial data processing and statistical table generation,
for documentation of the trial and incorporation into
statistical reports. This application is based on algorithms
and knowledge bases of clinical trial analysis methodology
and statistical analysis techniques, which are fully
compliant with ICH guidelines.
The main features include:
• Automatic identification of study populations
eligible for primary and secondary efficacy analyses,
and safety analysis
• Automatic selection of observations valid
for efficacy and safety analyses
• Automatic processing of temporal data
• Automatic data summarization
• Automatic generation of statistical reports
in accordance with ICH guidelines, including tabulations
and data listings of baseline data, efficacy data,
protocol deviations, compliance checking, adverse events,
clinical laboratory safety parameters, among others.
PANDA is a knowledge-based expert system. Its knowledge
bases contain representations of the rules governing
clinical trial data analysis and the presentation of
results. Most rules are formalizations of the ICH-E3
guidelines. Whenever the guidelines were ambiguous
or incomplete, the rules were extracted from the specialized
literature and adequately documented.
To illustrate the type of content in the knowledge
bases, the following figure displays the rules used
by PANDA for the identification of the different efficacy
populations for which any single study subject may
be eligible. PANDA recognizes five efficacy populations
(all randomized patients, intention-to-treat, all patients
treated, modified intention-to-treat and per protocol)
and one safety population.
The specific eligibility
criteria for each study population. To be eligible
for a specified study population, a subject must
fulfil all the criteria marked with. |
|
Criterion |
Definition |
ITT |
APT |
MITT |
PP |
Safety |
exclusion |
the subject was not discontinued
in the first study visit (start up visit) because
of without eligibility criteria or consent
withdrawn |
l |
l |
l |
l |
l |
screened out |
the subject was not discontinued
up to the inclusion visit because of without
eligibility criteria or consent withdrawn |
l |
l |
l |
l |
l |
late exclusion |
the subject was not discontinued
during treatment because of without eligibility
criteria |
l
|
l
|
l
|
l
|
|
baseline data |
the subject was observed in the
baseline visit |
l |
l |
l |
l |
l |
eligibility |
the subject had not a severe violation
in inclusion or exclusion criteria |
l |
l |
l |
l |
|
protocol violations |
the subject had not a protocol
violation or severe violation of any cause |
|
|
|
l |
|
compliance with medication |
the subject had at least one administration
of the study medication |
|
l |
l |
l |
l |
patient discontinuation |
the subject was not discontinued
during treatment for reasons other than adverse
events |
|
|
|
l |
|
efficacy data |
the subject had at least one evaluation
of efficacy data within the allowed window |
|
|
l |
|
|
missing efficacy data |
the subject had not a protocol
deviation missing efficacy data in the final
evaluation |
|
|
|
l |
|
Rules of that kind were developed for all aspects
related to clinical trial data analysis. For example,
for the identification of the visits valid for analysis
in each study population a complex set of rules had
to be defined.
PANDA also embodies algorithms for the analysis of
temporal data, which represent the largest part of
clinical trial data. Those algorithms are tolerant
to missing dates, in particular start and stop dates
of concomitant medications, a problem often encountered
in clinical trial data. PANDA uses all available information,
such as visits dates, to compute the time period when
a subject has been exposed to each treatment. The algorithm
deals effectively with all kinds of situations, including
open time intervals.
PANDA is extremely easy to use. Actually, its interface
consists only of a single screen, which is shown in
the following figure. The user just needs to select
the appropriate study, identify the population to be
used in the primary and secondary efficacy analysis,
and select the required reports from a list that includes
all the tables, tabulations and data listings defined
by the ICH E3 guideline.
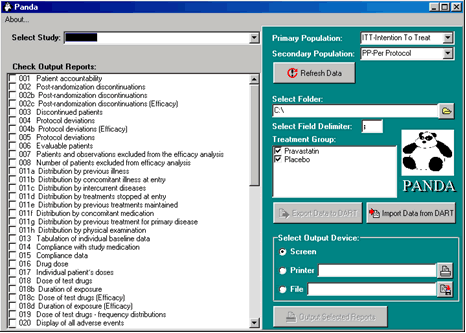
From then on, PANDA performs all data processing.
The application selects the subjects and observations
valid for each analysis, queries the COATI database
to collect the data needed for report generation, and
automatically generates and prints the reports. There
is absolutely no user intervention during this whole
phase of clinical trial data analysis.
For report generation, PANDA uses Business Objects,
a powerful software product for automatic query generation
and report preparation that is widely used in data
warehousing and data mining.
PANDA creates, in a matter of seconds, complex reports
that are error-free and that would take days to produce
manually. For example, the following report represents
just one of the several tables needed to report adverse
events in a statistical report. That table, according
to ICH specifications, has to combine information of
different nature, such as data on the adverse event
itself, the subject's demography, the dose of study
medication and the concomitant medication administered
during the period of the adverse event.
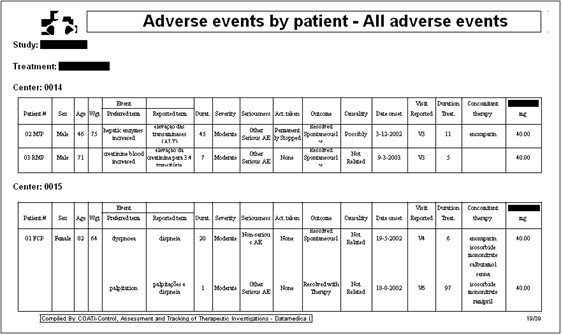
Many tables in a statistical report require, like
in the previous example, the combination of data from
different sources. The preparation of such tables imposes
the creation of multiple and complex database queries,
a process that has to be performed by database programmers.
One of the main advantages of a clinical trials information
system like COATI, which is based on a generic model
of the clinical trials paradigm, is clearly the elimination
of the need to create and validate ad-hoc queries for
each type of problem found in each clinical trial.
Another type of statistical tables that are difficult
to prepare manually are those containing classification
data, as for example the description of concomitant
medication. In order to create those tables, one needs
to classify each item in the appropriate class, and
then count the number of subjects exposed to each item
as well as the total exposed to that class. PANDA uses
its embedded controlled vocabularies for automatic
classification and counting, and presents the results
in a compact but perfectly readable table. An example
of a table for the description of concomitant medication
is shown below.
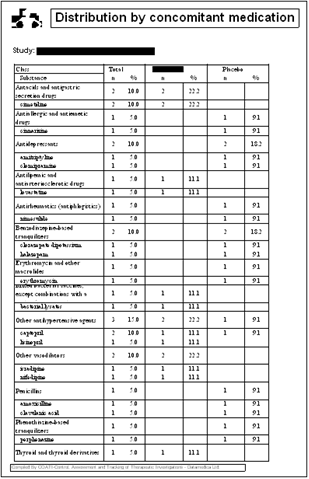
There are still other tables of higher degree of complexity.
All the clinical safety laboratory data, for example,
are extremely complex because of the number of data
items, the nature of the data and the several difficult
analyses required. For example, laboratory data may
be in a variety of units, and reference values often
vary across study laboratories.
For the analysis of laboratory data, PANDA starts
by converting every value into SI units. Next, it searches
the reference values adopted by each study laboratory,
converts them to SI units and identifies the observations
with values outside the reference range. Finally, it
creates the requested tables. All this process is entirely
automatic and does not require any user intervention.
The following example displays one of the tables required
by the ICH guidelines for the description of laboratory
abnormalities observed during the trial. This particular
case displays treatment-emergent laboratory changes.
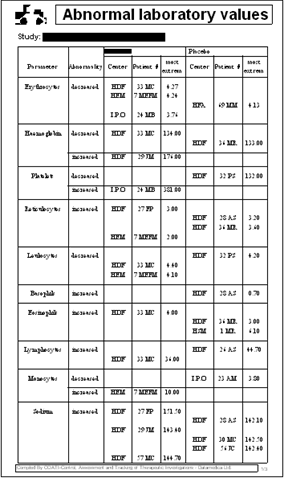
PANDA does not analyze efficacy data. That procedure
is performed by another component of the system, DART
(Data Analysis and Reporting Tool). However, PANDA
has a role in that process by selecting the data and
metadata needed for efficacy analysis, and by exporting
those data to DART. Once the data are processed by
DART, PANDA imports the results of the statistical
analysis and prepared the necessary reports.
PANDA generates automatically all the tables, data
tabulations and data listings required by the ICH E3
guidelines. The following list shows the tables prepared
by PANDA:
Conduct of the study
Patient accountability
Post-randomization discontinuations
Protocol deviations
Efficacy analysis
Number of patients excluded from efficacy analysis
Evaluable patients
Post-randomization discontinuations (primary efficacy
population)
Protocol deviations (primary efficacy population)
Distribution by concomitant illness
Distribution by concomitant medication
Drug dose
Compliance with the study medication
Safety analysis
Dose of test drugs
Duration of exposure
Dose of test drugs: frequency distributions
Adverse events - summary
Analysis of all adverse events
Display of all adverse events
Laboratory values over time
Laboratory measurements: change from baseline
Abnormal laboratory values
Abnormal laboratory values over time
Predefined change values over time
Abnormal vital signs values
Vital signs over time
Primary efficacy population
Distribution by concomitant illness
Distribution by previous illness
Distribution by previous treatment for primary disease
Distribution by treatments stopped at entry
Distribution by previous treatments maintained
Data listings
Discontinued patients
Protocol deviations
Patients and observations excluded from the efficacy
analysis
Tabulation of individual baseline data
Tabulation of individual efficacy data
Individual patient's doses
Compliance data
Adverse events by patient: all adverse events
Adverse events by patient: serious adverse events
Adverse events by patient: significant adverse events
Listing of individual laboratory measurements by patient
Individual patient changes
Listing of individual abnormal laboratory measurements
Listing of individual abnormal vital signs measurements
|